Quand l’hyper-threading devient contre-productif
Note préliminaire : je ne suis pas un spécialiste des processeurs et les explications que je donne ici reflètent ma compréhension de leur architecture. Je vous prie de bien vouloir me pardonner mes éventuelles approximations ou confusions et, le cas échéant, je vous invite à me signaler toute information qui pourrait améliorer ma compréhension et les explications que je donne, en vous en remerciant par avance. ;)
Le discours marketing est bien rôdé, les processeurs superscalaires qui animent nos machines voient leur puissance de traitement démultipliée grâce au multithreading, technologie dont le nom générique est simultaneous multithreading (SMT) et qu’Intel a popularisée sous l’appellation Hyper-Threading. Le multithreading consiste à exposer plusieurs « cœurs logiques » (communément appelés « threads ») en façade de chaque « cœur physique » (communément appelé « core »). Intel et AMD ont fait le choix d’exposer deux cœurs logiques pour chaque cœur physique, mais on peut concevoir un ratio différent.
En multipliant les petits pains à moindre cout, ces cœurs logiques semblent miraculeux. Mais le mirage a ses limites. De l’aveu même des fabricants, la technologie SMT n’augmente les performances globales du processeur que de 5 à 30 % selon le type d’application considéré, et non de 100 % comme on pourrait le croire à la lecture d’une plaquette commerciale prenant soin de nous épargner d’insipides détails techniques.
En effet, au niveau matériel, un cœur logique n’a strictement rien à voir avec un cœur physique, à tel point qu’on pourrait presque dire que c’est une vue de l’esprit et qu’il n’existe pas. Un cœur logique se résume à un ensemble de registres, un pointeur d’instruction et un contrôleur d’interruptions, le strict nécessaire pour gérer le contexte d’exécution d’un processus. Seul le cœur physique est doté d’une unité d’exécution, d’une unité de calcul arithmétique, d’une unité de calcul sur les flottants et des autres briques nécessaires au fonctionnement de ce qu’on appelle couramment un processeur. Il en découle que la puissance de calcul brute d’un processeur se mesure à son nombre de cœurs physiques et non à son nombre de cœurs logiques.
Le cœur logique serait-il une arnaque ? Pas tout à fait. Cette architecture se justifie par les incessantes interruptions du flux d’instructions induites par l’interaction du cœur physique avec les autres composants de l’ordinateur (entrées/sorties sources de latences). Ces interruptions font qu’un seul flux d’instructions exploite rarement le plein potentiel d’un cœur physique. En injectant plusieurs flux d’instructions en entrée d’un seul cœur physique, on améliore le taux d’occupation de ce cœur. De par son architecture superscalaire, il peut traiter les instructions venant d’un contexte pendant que l’autre est en attente d’entrées/sorties. C’est ce multiplexage et cette optimisation que permettent les cœurs logiques.
L’efficacité de cette approche repose donc sur un postulat : l’exécution des tâches est fréquemment interrompue. Lorsque ce postulat est vérifié, les cœurs logiques apportent effectivement un gain de performance. Mais lorsque les tâches n’engendrent que peu d’interruptions, comme c’est le cas d’un calcul intensif bien codé, les flux d’instructions sont « toujours » prêts à être exécutés. Ils se retrouvent en concurrence permanente, attendant que l’unité de traitement daigne leur accorder quelques cycles. La technologie SMT n’apporte alors aucun gain. Pire, la famine qu’elle engendre peut se révéler contre-productive en imposant inutilement les bascules de contextes, comme j’en ai récemment eu la démonstration éclatante.
Quand l’intégration continue met le processeur à rude épreuve
J’auto-héberge mes services sur un serveur, un NUC Intel NUC8i5BEH animé par un processeur Intel Core i5-8259U. Ce processeur est doté de la technologie Hyper-Threading. Il compte 4 cœurs physiques pour 8 cœurs logiques (processeur « 4 cores / 8 threads » ou « 4c/8t »). Comme mon serveur est sous-utilisé par mes services, j’y ai déployé un exécuteur Gitlab Runner au profit du projet libre Orekit, une bibliothèque de mécanique spatiale, i.e. de calcul de trajectoire de satellite. Après une courte phase de compilation, qui tire pleinement parti du multithreading, tant au niveau logiciel que matériel, le pipeline d’intégration continue lance de copieux tests parallélisés, qui sont pour l’essentiel des calculs mathématiques aussi complexes qu’intensifs.
Ce pipeline d’intégration continue soumet mon serveur à un stress intense pendant une quinzaine de minutes. Les cœurs fonctionnent à plein régime, ils montent en température et le ventilateur se prend pour un réacteur d’avion.
Pendant longtemps, je n’ai pas remis en question ce pipeline, j’ai laissé faire, d’autant plus que je ne connais rien à Java, langage dans lequel est développé Orekit.
Le 30 octobre 2023, j’ai constaté que ce pipeline mettait vraiment à mal mes
services, qui ne répondaient plus dans un délai acceptable. Je me suis
connecté sur mon serveur et j’ai découvert qu’il était soumis à une charge de
26, que le taux d’occupation des cœurs était de 100 % et que leur température
atteignait 100°C (température qu’ils ne dépassaient du fait d’une sécurité
matérielle qui abaisse leur fréquence de fonctionnement pour réduire leur
consommation énergétique et maintenir la température en dessous du seuil
critique). La commande htop m’a révélé que les tests étaient bien
parallélisés, exécutés par autant d’instances de la JVM qu’il y avait de
cœurs logiques sur mon processeur.
À cet instant, ce que je savais des processeurs m’est revenu en mémoire. La configuration du pipeline d’intégration continue m’a soudain parue bien trop optimiste. Ayant détecté 8 cœurs, Maven avait lancé 8 traitements en parallèle. Or, les tests effectuant surtout des calculs mathématiques méticuleusement optimisés pour exploiter au mieux les caractéristiques matérielles du processeur et minimiser les échanges de données avec la mémoire centrale, ils faisaient un usage optimal du cœur sur lequel ils s’exécutaient. Le processeur de mon serveur ne disposant que de 4 cœurs physiques, il ne possédait que 4 unités de calcul sur les flottants et non 8. Paralléliser les tests au-delà de 4 ne servait donc à rien, sinon à saturer les ressources matérielles et à faire grimper la charge du système (et accessoirement, à faire vieillir prématurément le processeur).
Un ami m’ayant expliqué comment cette parallélisation était configurée dans
Maven, j’ai soumis une micro-contribution au projet pour diviser
par deux le nombre de traitements lancés en parallèle, en remplaçant dans le
fichier de configuration de Maven (pom.xml) la ligne suivante :
<forkCount>1C</forkCount>
par celle-ci :
<forkCount>0.5C</forkCount>
Ce changement demande à Maven de ne lancer que 0,5 processus par cœur au lieu d’un, autrement dit, de lancer un processus pour deux cœurs. Mon serveur exposant 8 cœurs logiques, Maven allait lancer 4 processus au lieu de 8.
L’effet a été radical, il est même allé au-delà de mes espérances :
- La charge en pointe est passée de 26 à 11,5.
- Le taux d’occupation des cœurs est passé de 100 % en continu à 80 % (avec de courtes pointes à 100 %).
- Le pipeline consomme désormais 2,1 Go de mémoire vive en moins.
- Le temps d’exécution des tests unitaires a diminué de 5 %.
- Les autres services restent réactifs pendant que le pipeline s’exécute.
Bref, en lançant moins de processus en parallèle, le pipeline s’exécute plus vite, sollicite moins mon serveur et préserve les autres services. Que demander de plus ? :)
J’ai poussé un peu plus loin mon exploration du sujet en exécutant la même commande Maven en natif sur deux machines différentes, faisant toutes deux tourner la même version de la distribution Debian, du noyau, de Java et de Maven :
wombat(NUC produit en 2020) :- Processeur : Core i5-8259U 4 cœurs / 8 threads @ 2,3 GHz (Q3 2018)
- Mémoire : 32 Go de DDR4 2667 MHz
- Stockage : NVMe
errogol(PC portable produit en 2018) :- Processeur : Core i7-7700HQ 4 cœurs / 8 threads @ 2,8 GHz (Q1 2017)
- Mémoire : 32 Go de DDR4 2667 MHz
- Stockage : NVMe
Ces machines se distinguent donc essentiellement par leur processeur : Intel Core i5, de la famille mobile (U) de 8ème génération, contre Intel Core i7, de la famille haute performance (HQ), de 7ème génération.
J’ai exécuté les mêmes tests 3 fois sur chaque machine. Les valeurs présentées ici sont les moyennes obtenues :
mvn -Pgit,continous-integrationavecforkCount = 1C:wombat:- Durée : 15 min 43 s
- Occupation des threads : 100 % tout le temps
- Charge max. : 26,0
- RAM max. : 9,2 Go
errogol:- Durée : 10 min 29 s
- Occupation des threads : 100 % tout le temps
- Charge max. : 22,6
- RAM max. : 9,2 Go
mvn -Pgit,continous-integrationavecforkCount = 0.5C:wombat:- Durée : 15 min 0 s
- Occupation des threads : 80 %, avec courtes pointes à 100 %
- Charge max. : 11,5
- RAM max. : 7,1 Go
errogol:- Durée : 9 min 31 s
- Occupation des threads : 60 %, avec courtes pointes à 100 %
- Charge max. : 9,5
- RAM max. : 7,1 Go
On voit que l’impact de l’alignement du nombre de processus sur le nombre de
cœurs physiques est encore plus important sur la machine errogol, puisqu’on
gagne plus de 9 % de temps d’exécution.
Notez que je m’interroge sur l’écart de performance constaté entre les deux
processeurs. Il ne faut que 10 minutes à errogol pour exécuter les tests,
contre 15 minutes à wombat. Or, les comparatifs que l’on trouve sur le net
s’accordent à donner le processeur de wombat, plus récent, comme 15 % plus
performant que celui d’errogol. Comment expliquer cette contre-performance ?
Est-elle imputable à des comparatifs pour le coup trop généralistes qui, en
moyennant les performances mesurées sur des activités très variées, ne donnent
pas une image fidèle des performances en calcul sur les flottants ? Est-ce la
mauvaise dissipation thermique du NUC qui pénalise sévèrement son processeur
en le contraignant à abaisser sa fréquence de fonctionnement ? Sans doute un
peu des deux…
Pour en revenir au sujet de l’article, ce n’est pas la première fois que je constate un tel phénomène. En 2018, j’avais lancé un traitement d’image satellite (là encore, un processus qui effectue des calculs mathématiques intensifs sur des nombres flottants) sur un processeur Intel Core i7 doté de 8 cœurs physiques et 16 cœurs logiques. J’avais enchainé 9 exécutions du même traitement, commençant par un traitement non parallélisé, puis un traitement sur 2 cœurs, puis 4, puis 6 et ainsi de suite jusqu’à 16 cœurs. J’avais constaté une diminution progressive du temps de traitement entre 1 et 8 threads, puis une stagnation du temps jusqu’à 14 threads, puis une dégradation légère mais sensible au-delà :
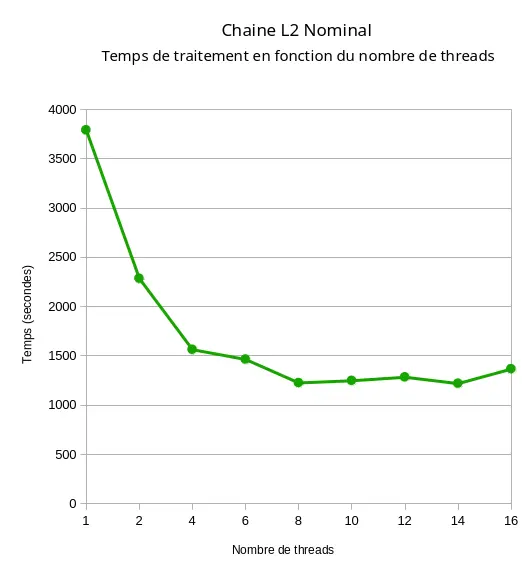
De nos jours, la plupart des processeurs intègrent une déclinaison ou une autre de la technologie SMT. Il me semble important d’en comprendre les arcanes pour ne pas trop attendre des processeurs et ne pas les soumettre à une charge qu’ils ne sont pas conçus pour encaisser efficacement.